图片来源:《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》
01
引言
后训练(post-training)已成为大模型完整训练流程中的重要组成部分。研究表明,这一阶段能够在推理任务上提升模型准确性,使其符合社会价值观并适应用户偏好,同时所需的计算资源相较于预训练(pre-training)较少。在推理能力的研究背景下,OpenAI 的 o1 系列模型率先通过CoT的长度引入了推断时扩展(inference-time scaling)技术,这一方法在诸如数学、编程、科学推理等任务上取得了显著进展。然而,有效的测试时扩展 (test-time scaling) 依然是研究界尚未解决的开放性问题。
一些先前的研究探索了不同的解决方案,包括基于过程的奖励模型、强化学习以及搜索算法,如蒙特卡罗树搜索和束搜索。然而,这些方法都未能达到与 OpenAI 的 o1 系列模型在通用推理能力上的同等水平。
DeepSeek首次尝试使用纯强化学习来提升语言模型的推理能力,旨在探索大语言模型在没有任何监督数据的情况下开发推理能力的潜力,重点关注其通过纯 RL 流程实现的自我演化。
具体来说,DeepSeek使用 DeepSeek-V3-Base作为基础模型,并采用 GRPO强化学习框架来提升模型在推理任务中的性能。
在训练过程中,DeepSeek-R1-Zero 自然地展现出许多强大而有趣的推理行为。经过数千步强化学习后,DeepSeek-R1-Zero 在推理基准测试中的表现大幅提升。例如,在 AIME 2024 基准测试中,pass@1得分从15.6% 提升至 71.0%,并在使用多数投票法后进一步提升至 86.7%,达到 OpenAI-o1-0912 的性能水平。
然而,DeepSeek-R1-Zero也面临着可读性差和语言混杂等问题。为了解决这些问题并进一步提升推理性能,DeepSeek引入了 DeepSeek-R1。该模型在强化学习之前加入了少量冷启动数据和多阶段训练管道。
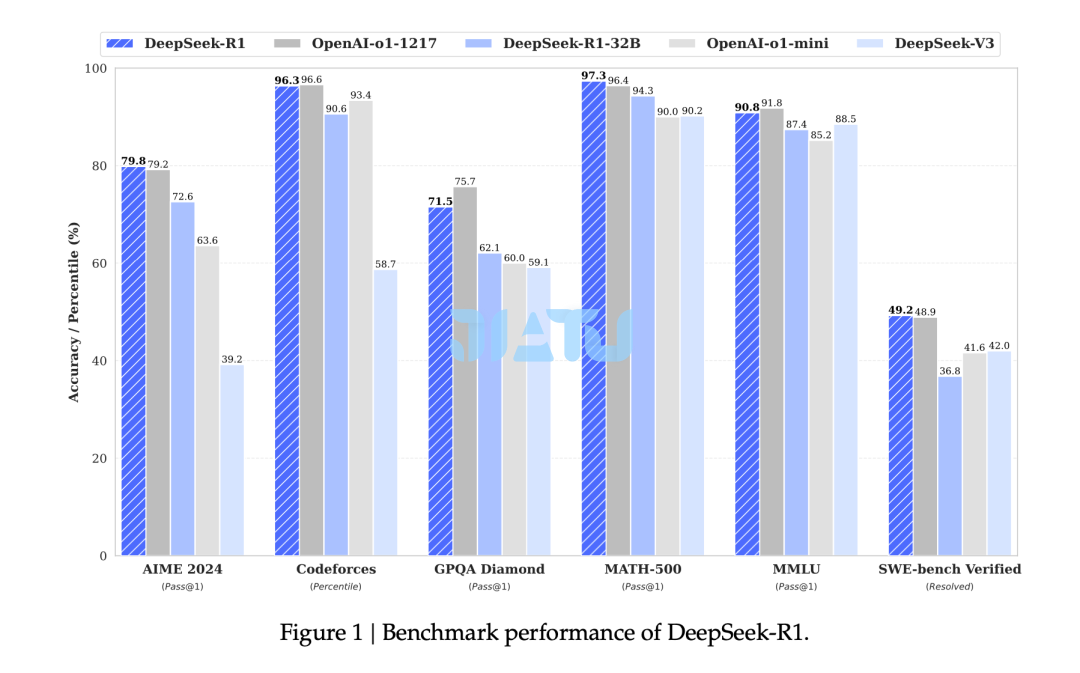
具体而言,DeepSeek首先收集了数千条冷启动数据对 DeepSeek-V3-Base 模型进行微调,随后与 DeepSeek-R1-Zero 类似,执行以推理为导向的强化学习。在强化学习过程接近收敛时,通过在 RL 检查点上进行拒绝采样,结合 DeepSeek-V3 的监督数据(包括写作、事实问答、以及自我认知等领域),生成新的SFT数据并重新训练模型。在微调完成后,该检查点继续进行强化学习,以涵盖所有场景的prompt。经过这些步骤后,得到了名为 DeepSeek-R1 的检查点,其在推理任务上的表现与 OpenAI-o1-1217 相当。
原文太长,微信不支持,点击【查看详情】继续阅读!





